Interpreting Chat Actors

601,705
messages
4,565
conversations
9,731
users
We studied the community dynamics of Ubuntu IRC forums over one month. Through this study, we tracked the development of the chat network over time and examined dynamic participation patterns. We also observed factors that affect a user's embeddedness in the network and their 'importance' as discussion initiators or responders. These findings informed a web application that predicts the best times for discussion on a given topic for practical collaboration.
Project Type: social network analysis, data visualization, front-end development
Role: graph visualization, data mining, UX design, prototyping, front-end development
Tools: Python (BeautifulSoup, scikit-learn) for data mining, Gephi for graph visualization, Python (matplotlib, seaborn) for visualization, Figma for design and prototyping, Python (Tkinter) for app development
Date: February - April 2019
Code: GitHub
Context
Open source software holds advantages over proprietary software in terms of security, cost, and flexibility. Because these products are widely used, they are also rapidly deployed for performance assessment. Developers often create specialized support forums called Internet Relay Chats (IRCs) to help users navigate these changes. IRCs provide opportunities for leveraging computing methods to increase collaboration across a large community.
The Objective
The primary objective of this study was to decipher connections and restructure communication strategies among users in the channel to facilitate information flow. These strategies could guide a variety of users towards achieving their desired objectives via online communication. Our analysis aimed to:
- Construct a community model for information flow. This model could be used to create collaborative learning tools that assess knowledge transfer in online communities and to filter IRC participants based on their interests for greater efficiency.
- Benefit open source developers and the learning community at large by capturing the discussion rate for a particular topic. For example, an increase in traffic on a connection could enable us to extract and leverage the popularity of a concept by mining linguistic patterns through bots to motivate other groups of people. It could also help match users to appropriate chat rooms based on the user's tastes and their optimized queries.
The Process
1. Data cleaning and feature analysis
The biggest advantage of the Ubuntu IRC over other IRCs is that it follows a peer-to-peer approach towards primarily software-related discussions, which allows for research that applies to other technical domains like business, collaborative learning, and military control. As more and more people join the IRC, they provide diverse approaches to problem-solving, thereby increasing the quality of solutions. This community thus evolves as a goal-oriented community, where the primary objective is to facilitate discussions.
Our dataset contained 601,705 messages from 9,731 users. To build the chat corpus, we scraped Ubuntu technical support channel logs. Each message had four relevant properties: channel, timestamp, username, and data.
2. Community Analysis
Participants were divided into 'experts' and 'non-experts' – users with high network authority scores (high input and output content nodes) were labelled experts and the rest were labelled non-experts. This notion of role-influenced behaviour taken from centralized systems helped us informally discover the nature of these social interactions if such roles were mapped to conversations.
We used reply structure and word context techniques to extract a network from the data. Because IRC etiquette states that users address each other directly ('@___'), we were able to establish ties between participants. The network consisted of outward links from message senders to recipients. Multiple references built stronger ties between the corresponding nodes (users). Thus, our directed weighted network consisted of IRC users as nodes, with the edge weights corresponding to their communication frequency. Nodes were sized according to the betweenness centrality of the participant. Finally, sub-networks were coloured according to their modularity classes.

Information gained from this visualization
- The network has 9,731 nodes (users) and 41,832 edges (directed messages).
- The graph has an average path length of 4.3, which means every node is connected to every other node through an average of 4 nodes. The low average path length indicates that there are very few disconnected components in this network. Indeed, the network had only 83 weakly connected components compared to 4,230 strongly connected components.
- An average degree of 4.29 also means that one user replied to 4 distinct questions on average, with 'experts' having much higher weights associated with their output edges. This indicates that experts engage primarily in detailed discussions on shared problems, rather than giving short and objective replies to singular queries.
- Networks with high modularity have dense connections between nodes within modules but sparse connections between nodes in different modules. This dataset shows a modularity of 0.712, with 108 communities in total. This means that users could be split into 108 communities such that they interact much more with users in their own community than those in other communities.
3. Topic Detection
Often, participants on an open forum such as IRC are subjected to long wait times until their queries are resolved. If an expert is unavailable for a long time, the question can get buried under others and eventually remain unsolved, leading to a lossy information exchange. We identified the times of day when experts discussed a topic to help new users predict when their query would most likely be resolved.
The machine learning approaches we used for studying linguistic behaviour and topic models[1] are based on the assumption that the corpus is dynamic. Therefore we developed an indicative term-based categorization approach using chat sessionization and keyword mining. We restricted the report to hour-long bins to ensure that the analysis is neither too narrow nor too broad.
4. Web Interface
I incorporated this approach into a user-facing and administrator-operated message analysis system.
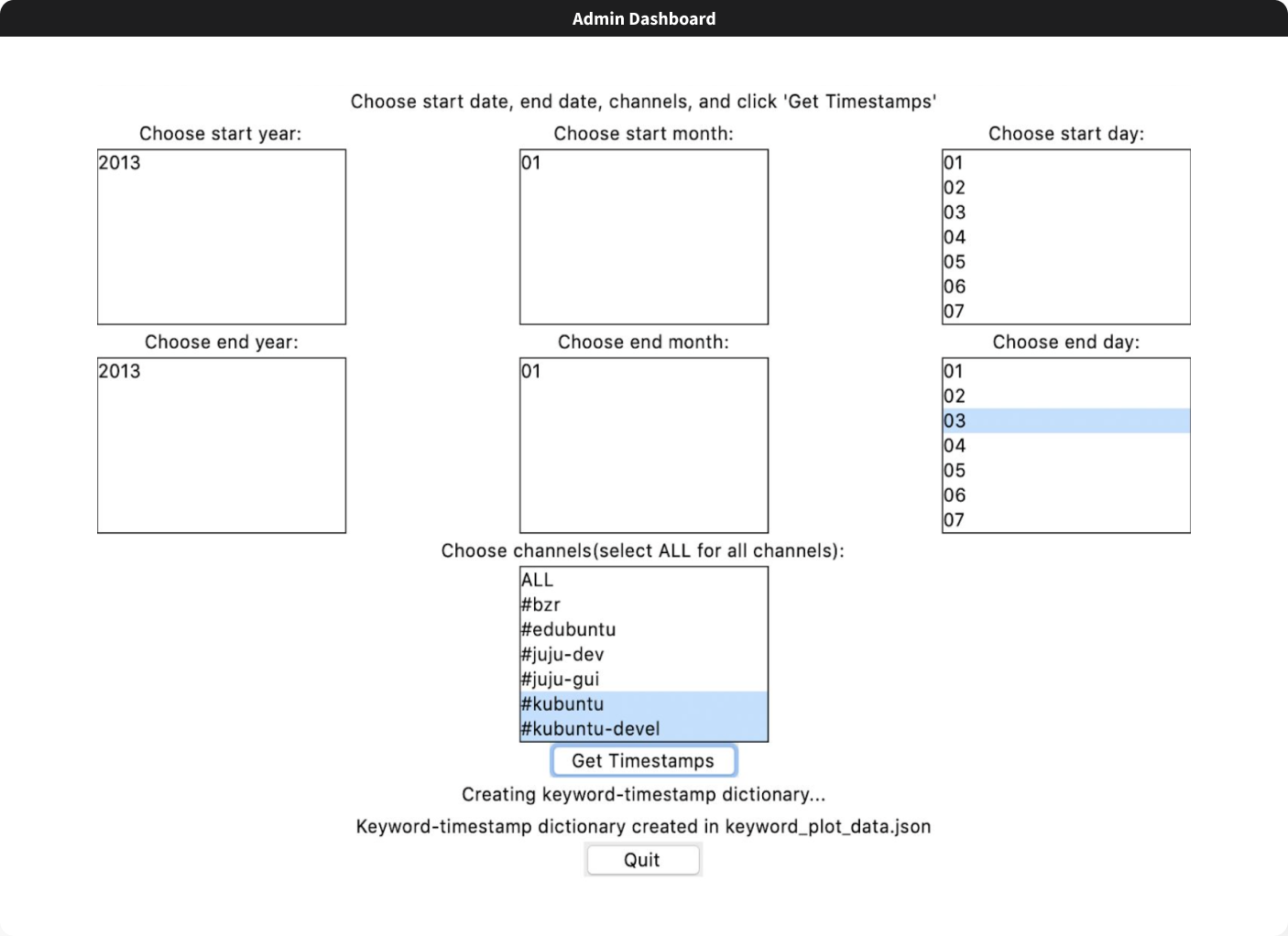
Application workflow
- An administrator selects the period for which they want to parse the IRC chat logs
- A keyword-timestamp dictionary is created
- Experts' messages are parsed for keywords and corresponding timestamps are stored as a keyword-timestamp dictionary in a JSON file
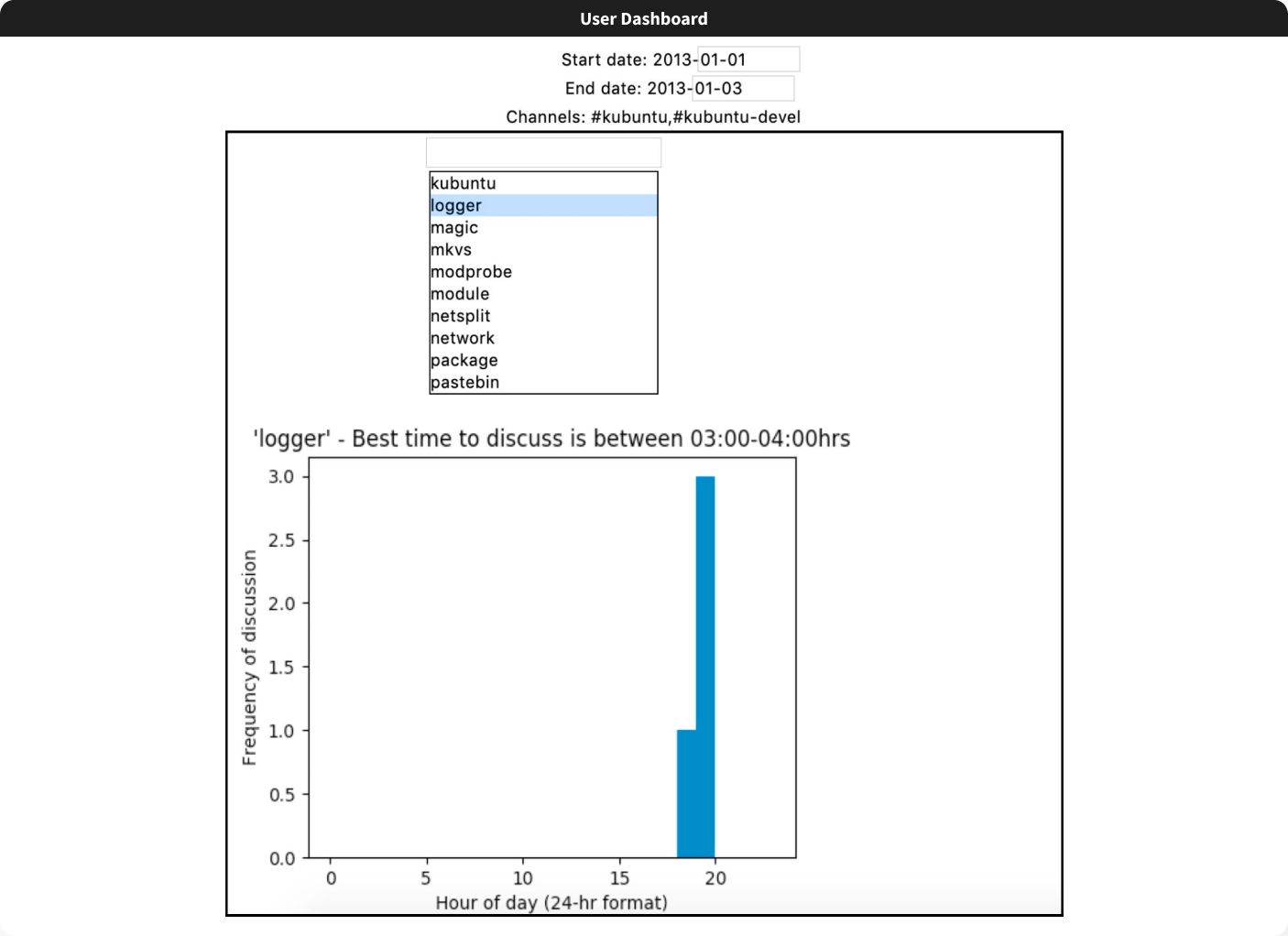
- Whenever a new user wants to operate the system, they select one or more keywords from a drop-down list extracted from the set of data parsed by the administrator
- The application produces a 'frequency of discussion' vs 'hour of day' plot for each selected keyword based on the data in the dictionary
Outcome Highlights
It was interesting to examine IRCs because "people who are located in geographically distant locales, who are of different national and linguistic backgrounds, and who might otherwise never come into contact, can engage in real-time interactions that resemble the immediacy of in-person face-to-face encounters"[2]. We provided:
- a new perspective to examine the network skeleton patterns of relationships between people, and
- a user-friendly application for topic detection, increasing the efficiency and ease of usage of the forum substantially for new users.
Further Improvements
- This analysis relies heavily on the availability of large amounts of data for a specific period. Further work can be done to make this system more robust by undergoing multiple iterations on different datasets.
- Running a python application is not ideal if we consider a wider range of use cases. This model can be used to create a decentralized application for real-time user engagement.
- Detecting the ideal hours of the day is a basic approach to the topic detection problem. It can be expanded to a much larger scale using larger buckets of time coupled with other properties like user location.
References
[1] Guille, Adrien, Hakim Hacid, Cécile Favre, and Djamel A. Zighed. “Information diffusion in online social networks: A survey.” ACM SIGMOD Record 42, no. 1 (2013): 17-28.
[2] Paolillo, John. “The virtual speech community: Social network and language variation on IRC.” Journal of Computer-Mediated Communication 4.4 (1999): 0-0.